Llama3 just got ears



We’re excited to share llama3-s v0.2 (opens in a new tab), our latest multimodal checkpoint with improved speech understanding.
Demo
A realtime demo of Llama3-Speech (23th Aug 2024 checkpoint): the MLLM listens to human speech and responds in text
Llama3-s v0.2 consistently performs across multiple Speech Understanding benchmarks (see Results). While more analysis is needed, we’re excited to share this progress with the community and get feedback.
You can try it for yourself:
- Via our self-hosted demo here (opens in a new tab)*
- Via Hugging Face demo here (opens in a new tab)*
- Build it from scratch (opens in a new tab)
*Inference may slow/queued due to shared compute
*For this round, please ask questions in English and keep them under 10 seconds long. This is due to our model's limitation in being trained on audio prompts with fewer than 500 tokens, which we plan to address in a future update.
This post shares results and methodology behind an Aug 20th checkpoint. As always, this is just the beginning, and we need your ideas to push this research further.
💡 We invite you to join llama3-s (opens in a new tab): an ongoing, open-source, and open-data research experiment teaching llama3 to listen. See motivation (opens in a new tab).
Architecture
In a previous post (opens in a new tab), we shared llama3-s v0.1 (opens in a new tab), an early-fusion experiment where we instruct-tuned llama3 on encodec’s (opens in a new tab) acoustic tokens [fig 1]. While we observed some transitivity between the LLM’s text and new audio tokens, there were imminent limitations like the lack of generalization to non-synthetic voices, among other issues (opens in a new tab).
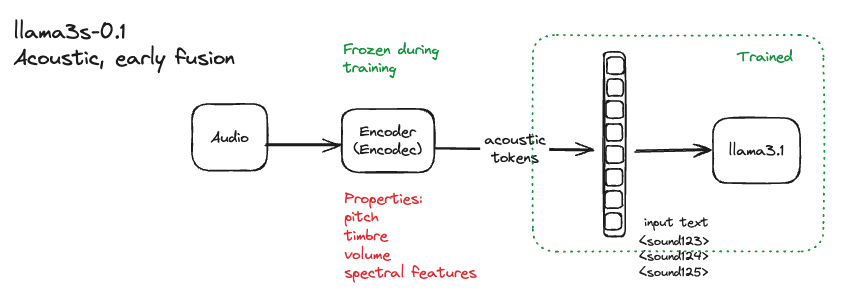 Fig 1. our previous acoustic tokens early-fusion experiment
Fig 1. our previous acoustic tokens early-fusion experiment
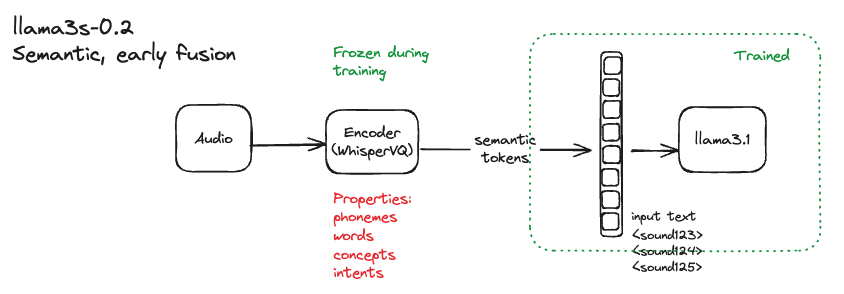 Fig 2: the current approach is early-fusion with semantic tokens
Fig 2: the current approach is early-fusion with semantic tokens
For llama3-s v0.2, we adapted llama3.1 using early-fusion with semantic tokens, inspired by community feedback (opens in a new tab) [fig 2]. Our goal is to leverage the benefits of semantic tokens, such as simplicity, better compression, and consistent speech-feature extraction, as demonstrated by WhisperVQ (opens in a new tab). We can always scale up to a hybrid approach and reintroduce acoustic features as needed, given more data and compute resources.
You can learn more about our comparison of semantic and acoustic tokens here.
Training
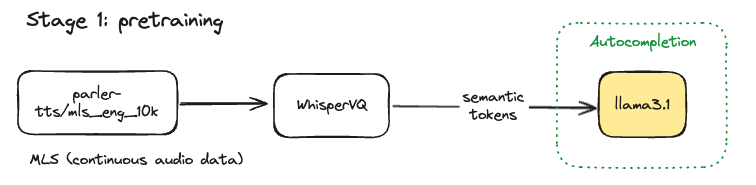
Stage 1: pre-training on real speech
We found it useful to pre-train llama3.1 on continuous speech, through rough ablation experimentation. This enhanced llama3’s ability to generalize across semantic tokens.
Data: We used the MLS-10k dataset (opens in a new tab) (10 hours of unlabeled, multilingual human speech courtesy of OpenSLR) to pre-train llama3.1 8b on next token prediction (code here (opens in a new tab)).
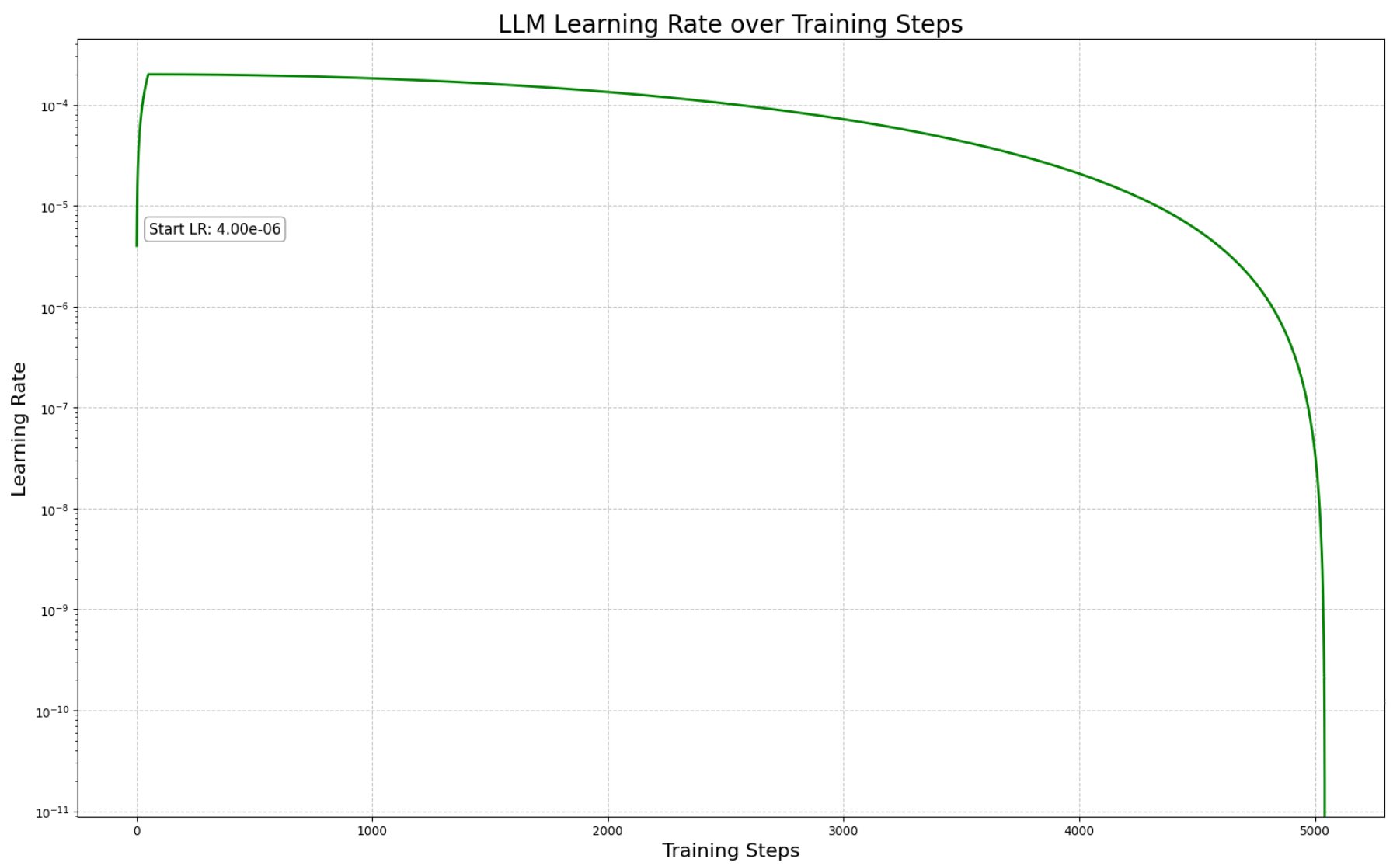
Training: The pretraining totaled 5k steps and took over 30 hours*. We used Torchtune’s (opens in a new tab) fully sharded data parallels, an AdamW Fused optimizer, along with the following parameters:
| Parameter | Continual Training |
|---|---|
| Epoch | 1 |
| Global batch size | 80 |
| Learning Rate | 2e-4 |
| Learning Scheduler | LambdaLR with warmup |
| Optimizer | AdamW Fused (opens in a new tab) |
| Warmup Steps | 20 |
| Weight Decay | 0.01 |
| Gradient Checkpointing | Full |
| Max length | 512 |
| Precision | bf16 |
The learning rate schedule is as follows, starting with a relatively high LR for sufficient warmup.
Loss: After 5000 steps, loss converged at just below 2, at which point we simply moved onto the next stage.
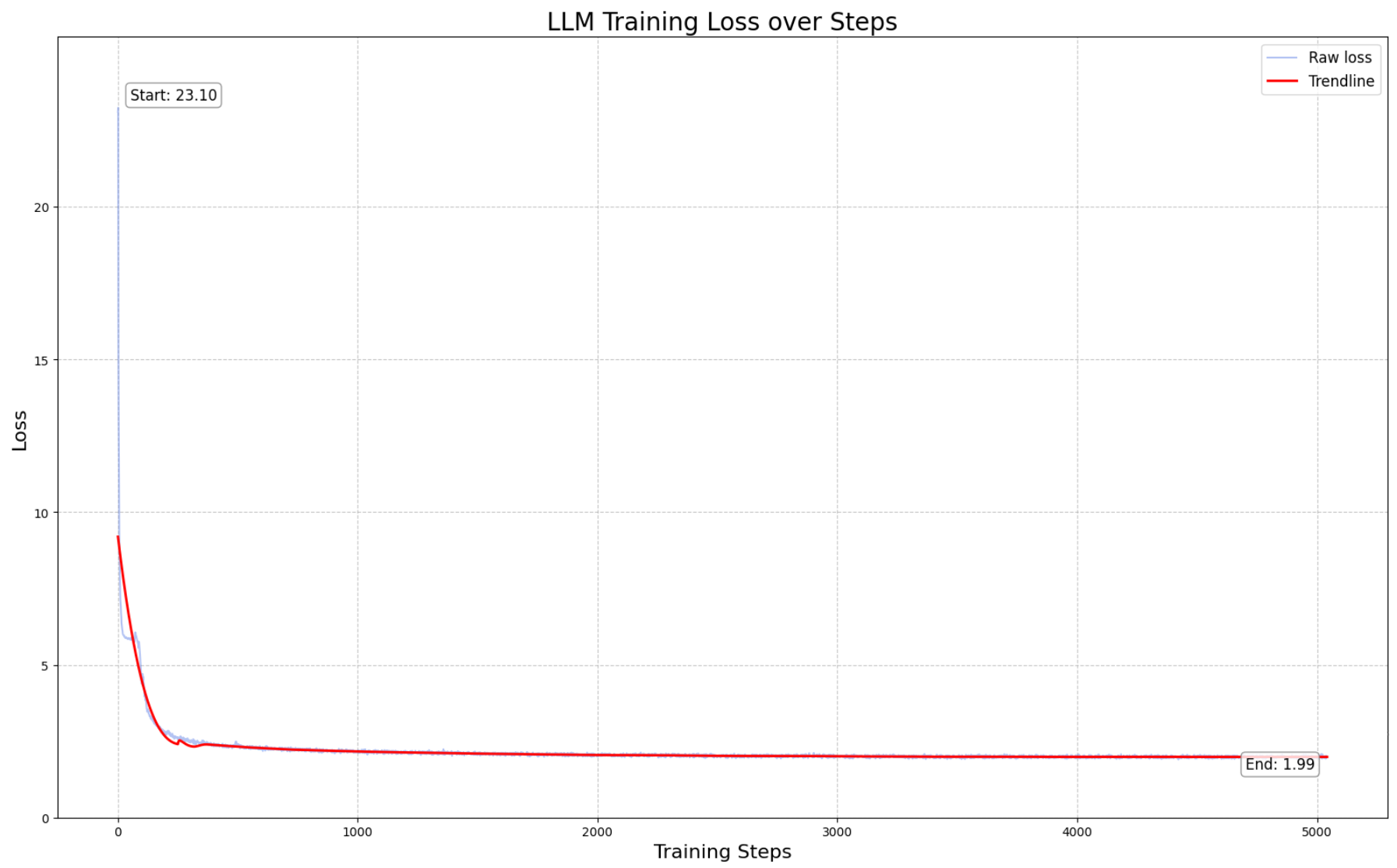
Compute: We used a single 10x RTX A6000 node to train. We actually own and operate our own A6000’s node that we’ve fondly named “Boba”. So, to get a rough cost calculation for this stage, let us assume a higher end rate of USD0.80 per GPU, totaling $240 for the pre-train.
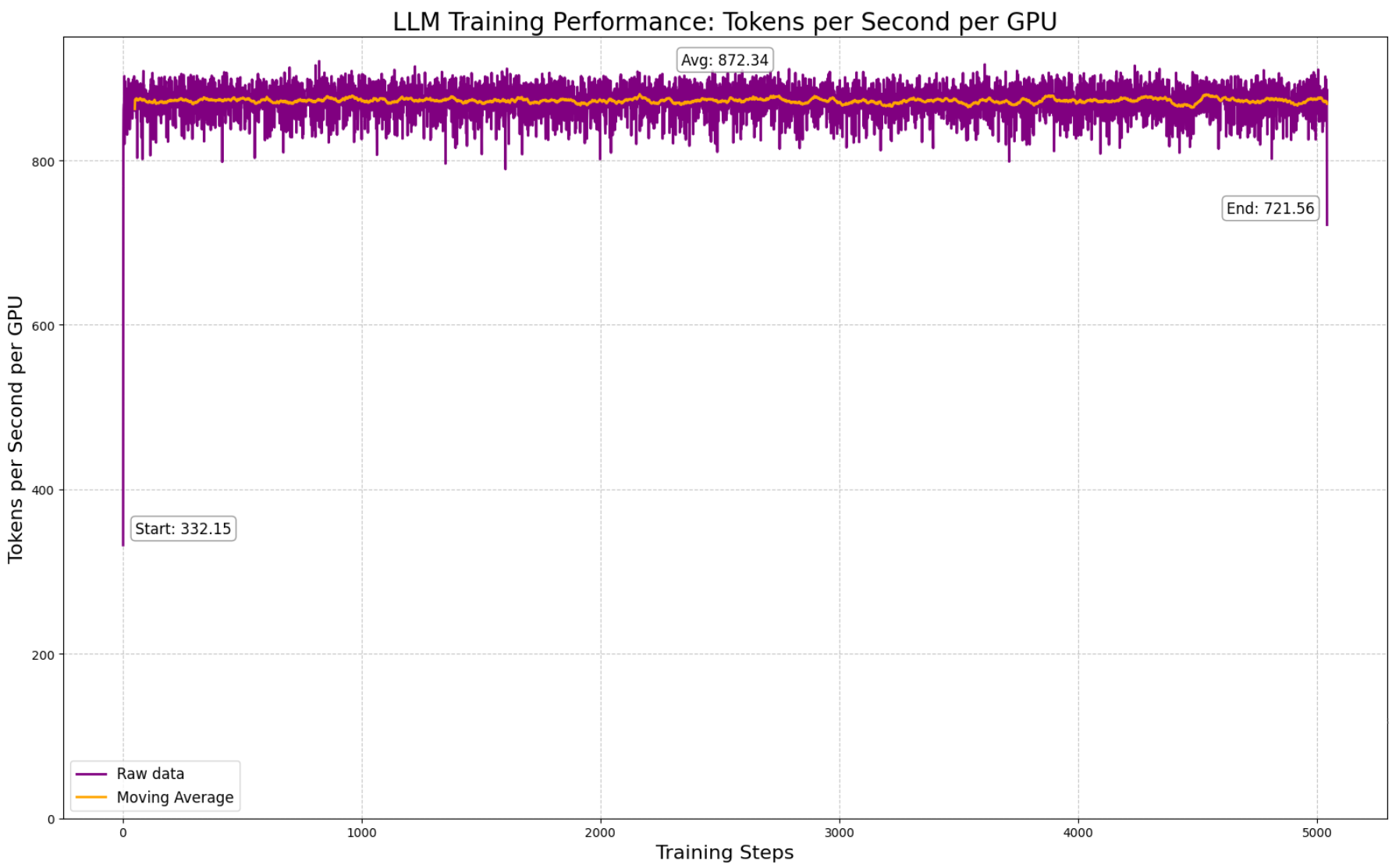
MMLU Eval: We measured MMLU at this stage to get a sense of degradation. 0-shot MMLU dropped from 0.63 → 0.46, a 30% decrease that we hoped to recover in the subsequent stage.
Stage 2: instruct tuning on a mixture of synthetic data
For the second stage of training, we instruct-tuned llama3 with interleaving synthetic data.
Data: We use a synthetically generated speech dataset (opens in a new tab). This speech data is then semantically encoded with WhisperVQ (opens in a new tab) from WhisperSpeech (opens in a new tab). This dataset was then interleaved to have 70% speech instruction prompts and 30% speech transcription prompts.
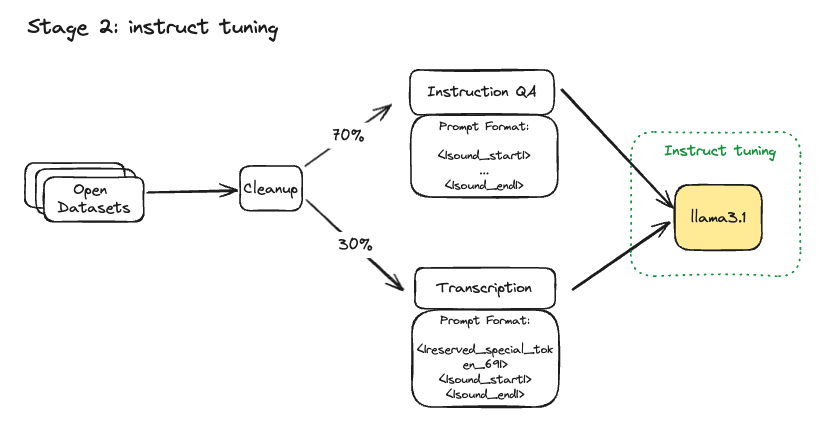
Training: The instruct tuning was done with fsdp2, mixed-precision, with the final weights in bf16. We used the AdamW Fused optimizer, a global batchsize of 128 (mini-batches of 2-4), a 0.5e-4 LR, and Cosine learning scheduler. You can find the full steps to reproduce our training here (opens in a new tab).
| Parameter | Continual Training |
|---|---|
| Epoch | 1 |
| Global batch size | 128 |
| Learning Rate | 0.5e-4 |
| Learning Scheduler | Cosine with warmup |
| Optimizer | AdamW Fused (opens in a new tab) |
| Warmup Steps | 73 |
| Weight Decay | 0.005 |
| Gradient Checkpointing | Full |
| Max length | 1024 |
| Precision | bf16 |
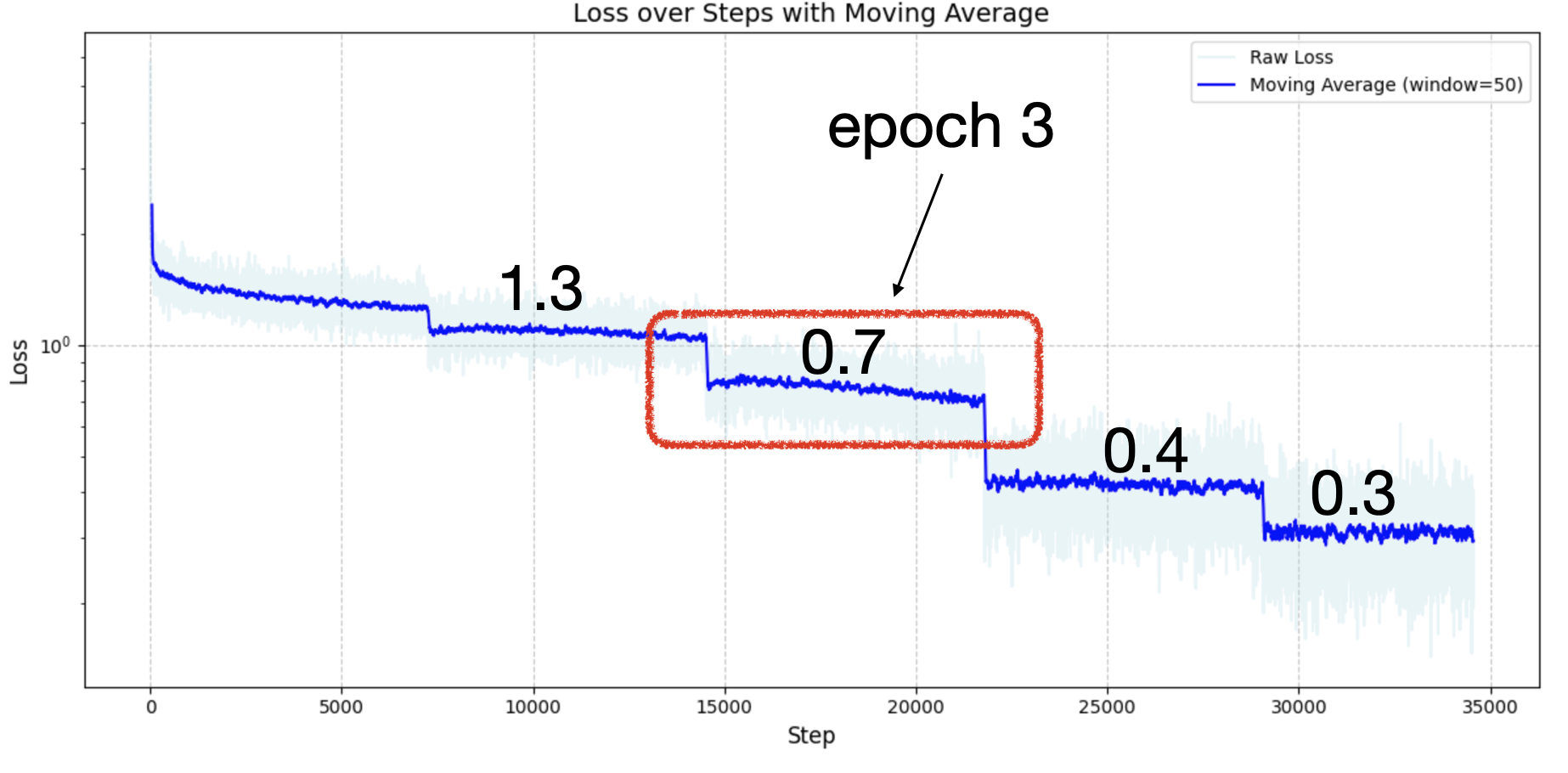
Compute: The training took place over 32 hours on 8x H100s, spanning 5 epochs at 6 hours & 7261 steps per epoch. At $2.20 per H100 per hour, we estimate this run to have costed $563, not including several failed runs due to troubleshooting.
Model Flops Utilization (MFU) per step is around 20-25% (opens in a new tab), which is hugely optimizable. It’s also worth mentioning that we intentionally overtrained at this stage to run some grokking (opens in a new tab) experiments.
In total, both stages of training was achievable under $600, with the entire experiment coming under $2800, accounting for various data pipelines and failed runs due to bugs and infrastructure interruptions.
Results
We found epoch 3 to be performant and is our current demo checkpoint.
AudioBench Eval: AudioBench (opens in a new tab) is a June 2024 benchmark designed to evaluate audio large language models (AudioLLMs). It measures speech capabilities, in addition to ASR, transcription, etc., through a compilation of many open datasets.
| Model Bench | Open-hermes Instruction Audio (opens in a new tab)(GPT-4-O judge 0:5) | Alpaca Instruction Audio (opens in a new tab)(GPT-4-O judge 0:5) | Librispeech clean v2 (opens in a new tab) (ASR) (WER score) |
|---|---|---|---|
| Llama3.1-s-v2-epoch-1 (opens in a new tab) | 3.02 | 2.87 | 94.66% |
| Llama3.1-s-v2-epoch-2 (opens in a new tab) | 3.0 | 3.22 | 60.80% |
| Llama3.1-s-v2-epoch-3 (opens in a new tab) | 3.45 | 3.53 | 49.98% |
| Llama3.1-s-v2-epoch-4 (opens in a new tab) | 3.47 | 2.93 | 60.05% |
| Llama3.1-s-v2-epoch-5 (opens in a new tab) | 3.34 | 3.01 | 69.07% |
Our training dataset didn’t contain Alpaca Instruction. At epoch 3, llama3-s v.02 achieved an average score of 3.53 on the ALPACA-Audio eval, which seems to beat SALMONN, Qwen-Audio and WavLLM.
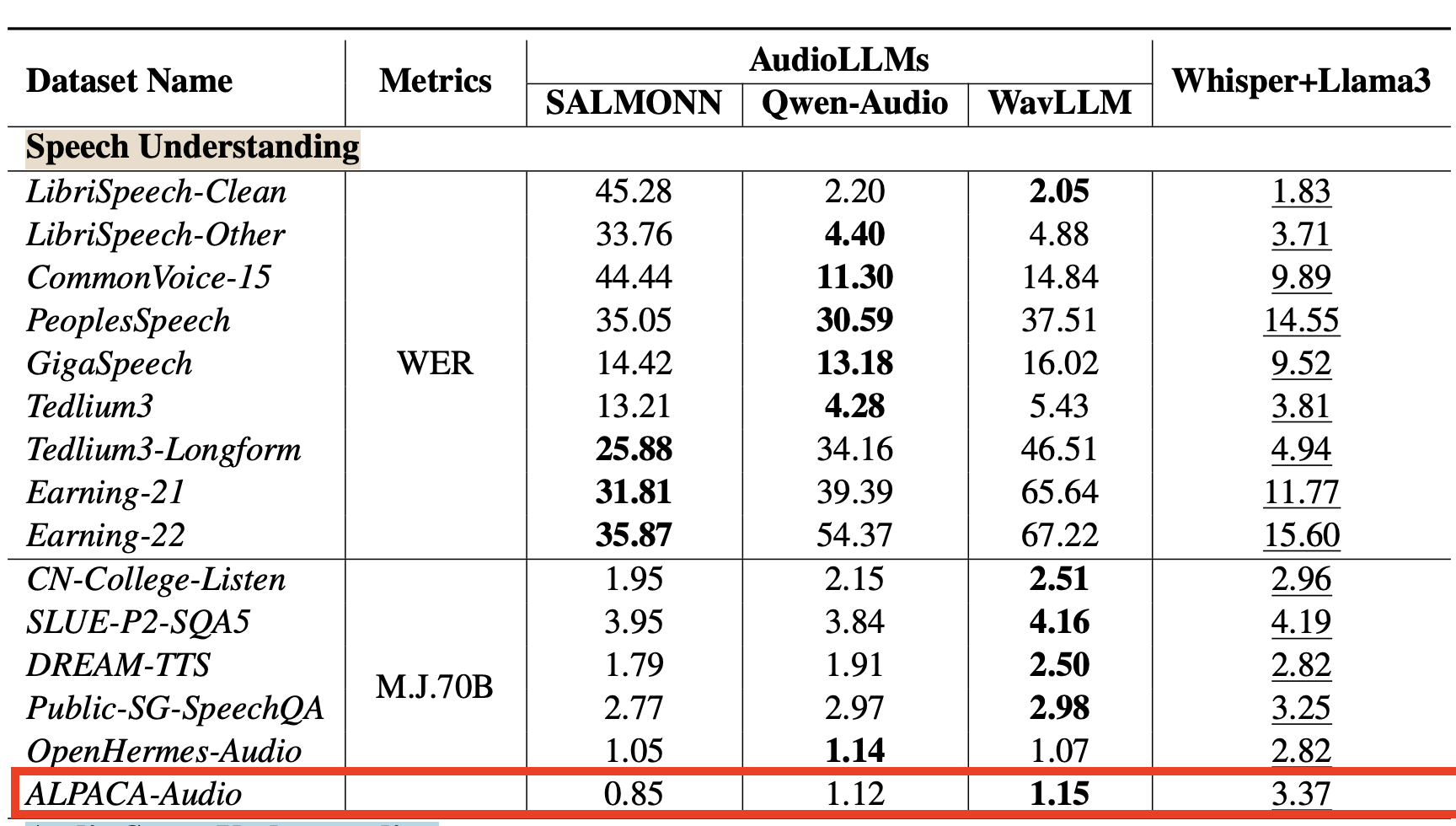 Fig 3: SOTA models evaluated on AudioBench
Fig 3: SOTA models evaluated on AudioBench
The overfitting started in epoch 4. It is interesting to observe that OpenHermes-Audio eval remaining high after this epoch, likely indicative of some training data contamination. Thus we are inclined to disregard the OpenHermes-Audio criterion.
This checkpoint is bad at ASR, which wasn’t our target, but we included it for good measure.
MMLU eval: Base llama3.1 has an MMLU score of 0.6380, and degrades to the following across our epochs.
| MMLU | Degradation (%) | |
|---|---|---|
| Epoch 1 | 0.5139 | 19.45 |
| Epoch 2 | 0.4621 | 27.57 |
| Epoch 3 | 0.4676 | 26.71 |
| Epoch 4 | 0.4720 | 26.02 |
| Epoch 5 | 0.4703 | 26.29 |
Next Steps
Llama 3.1 v0.2 is still in its early development and has limitations:
- Model is sensitive to bad compression on the incoming audio
- Model cannot listen to >10s audio and get confused
- Very weak to nonsensical audio and will need to be trained on noise
Additionally, our current approach, a Type D.1 (opens in a new tab) multimodal model, has well studied limitations. Namely, there are challenges to scaling the tokenizers and a lack of fine-grained control of how modality information flows in the model. This current approach possibly requires more training data down the road as a tradeoff for its architectural simplicity.
For now, our next steps are as follows:
- Curate training dataset better, longer prompts, filtering out non-speech-perfect data
- A more efficient synthetic data pipeline that skips redundant layers
- Establishing cascaded system baseline benchmarks to evaluate computational and latency improvements
- Exploring other model architectures that are more efficient
Long term, we aim to develop an open, multi-turn speech model for llama3-s that excels in low-resource languages, with a focus on improving generalization across ASEAN's diverse accents and dialects. Achieving this will necessitate a significant and sustained data collection effort.
Acoustic v Semantic
tldr: Acoustic tokens, though more rich in audio features, requires large training data and computational resources.
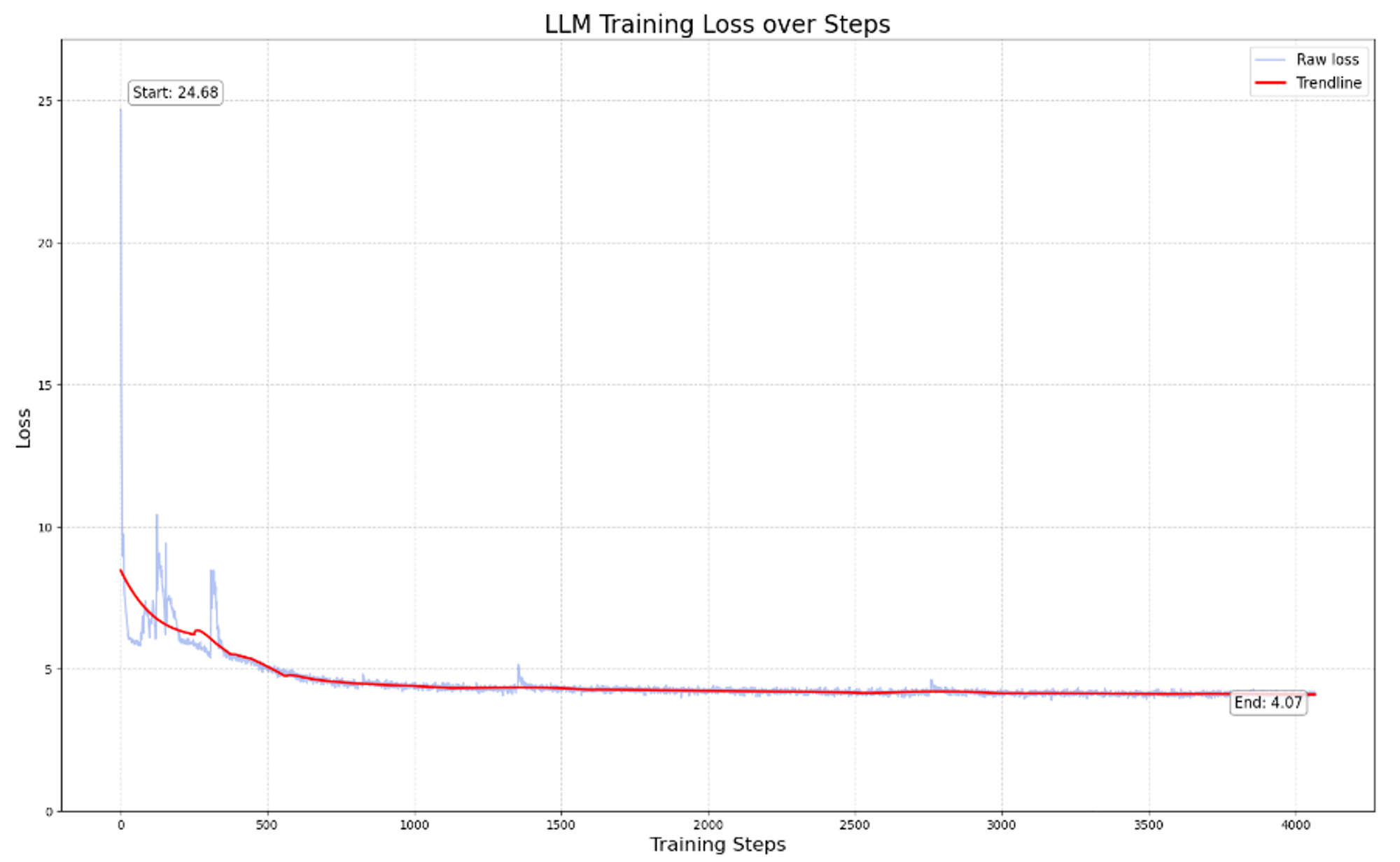
The loss on our acoustic tokens pre-training were largely stuck at 4.
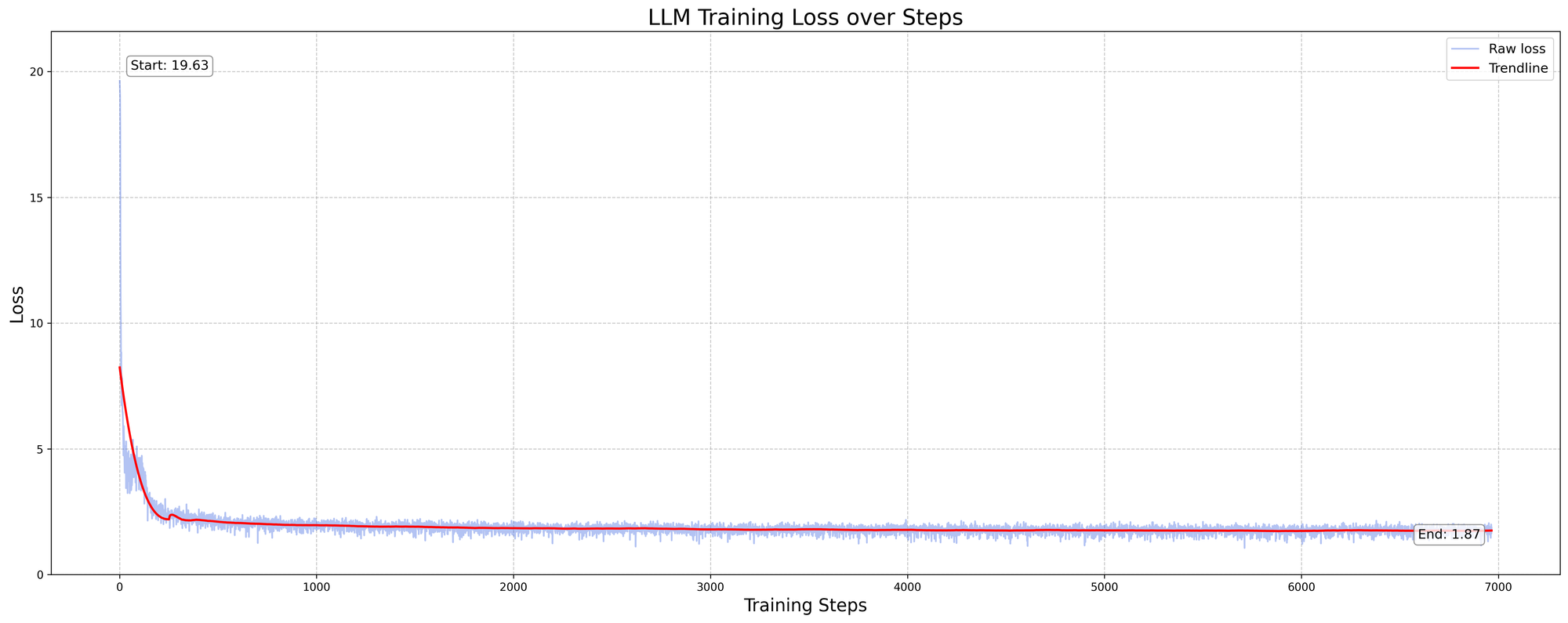
Where as pretraining on semantic tokens converged to ~1.8 after 7k steps.
Acknowledgements
- OpenSLR (opens in a new tab)
- Torchtune (opens in a new tab)
- The Evolution of Multimodal Model Architectures (opens in a new tab)
- Whisper: Robust Speech Recognition via Large-Scale Weak Supervision (opens in a new tab)
- Collabora’s WhisperSpeech (with data from LAION) (opens in a new tab)
- AudioBench: A Universal Benchmark for Audio Large Language Models (opens in a new tab)
- Chameleon: Mixed-Modal Early-Fusion Foundation Models (opens in a new tab)
- Why Warmup the Learning Rate? Underlying Mechanisms and Improvements (opens in a new tab)
- Yip Jia Qi (opens in a new tab): Discrete Audio and Speech Benchmarks (opens in a new tab)
- Discord Contributors (opens in a new tab): @gau.nerst, @hydroxide, @Blanchon.jl
Open Call
We’re calling on LLM researchers and audio experts to experiment with us.
Join the Discord fun:
- #research (opens in a new tab) : general research & paper sharing
- #llama3-s (opens in a new tab): daily
argumentsdiscussions - #research-livestream (opens in a new tab): live training & lo-fi music 😂
We believe that collaborative, open research can accelerate progress in this exciting field. Whether you're an experienced researcher or an enthusiastic newcomer, your contribution could be valuable.
At Homebrew Computer Company (opens in a new tab), we like smaller, “edge friendly” models that are privacy preserving and feasible to train on energy-efficient clusters. Read more about our AI philosophy here (opens in a new tab).


The Soul of a New Machine
To stay updated on all of Homebrew's research, subscribe to The Soul of a New Machine