Can llama learn to listen?




We invite you to join llama3-s (opens in a new tab): an open and ongoing research experiment focused on teaching llama3 to listen. This blog post is a quick project update and an open call to join us in building a speech adapter for open-source models.
Inspired by the Chameleon (opens in a new tab) and Llama Herd (opens in a new tab) papers, llama3-s is an early-fusion, audio and text, multimodal model. We're conducting this research entirely in the open, with an open-source codebase (opens in a new tab), open data (opens in a new tab) and open weights (opens in a new tab).
Gradio Demo (19 July 2024): the model “listens” to audio files and does text autocompletion
Our initial approach uses a sound compressor to create discrete token representations of sound, which are then used to train the LLM. We hypothesize that these sound tokens can be continuously learned and that existing text-based models can find semantic connections between sound and text representations.
In this post, we share results from a July 19th checkpoint (opens in a new tab). We trained llama3 8b on synthetic audio, via a small training run that cost less than $600, yielding interesting results. But this is just the beginning, and we need your expertise and ideas to push this research further.
 Image Credit: When llama learns to listen by Cary & Kumar
Image Credit: When llama learns to listen by Cary & Kumar
The Problem
Cascaded systems (opens in a new tab) (currently popular in production) take user speech, transcribe it into text, and pass it into an LLM. They have been proven to be slow, inefficient, and lossy (opens in a new tab).
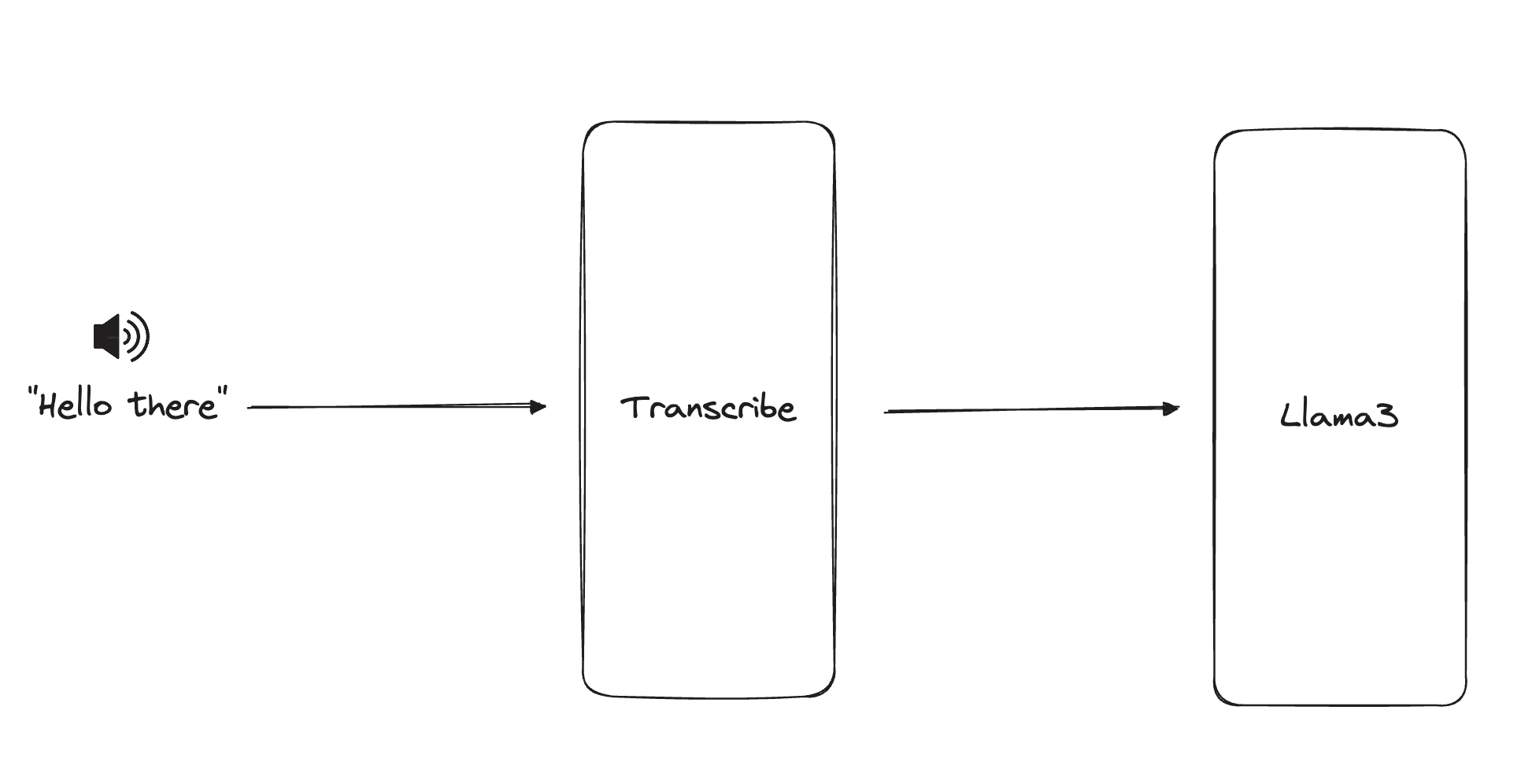 Pictured: Cascaded systems use two separate models. In addition to latency, emotion, tone, many audio features are lost.
Pictured: Cascaded systems use two separate models. In addition to latency, emotion, tone, many audio features are lost.
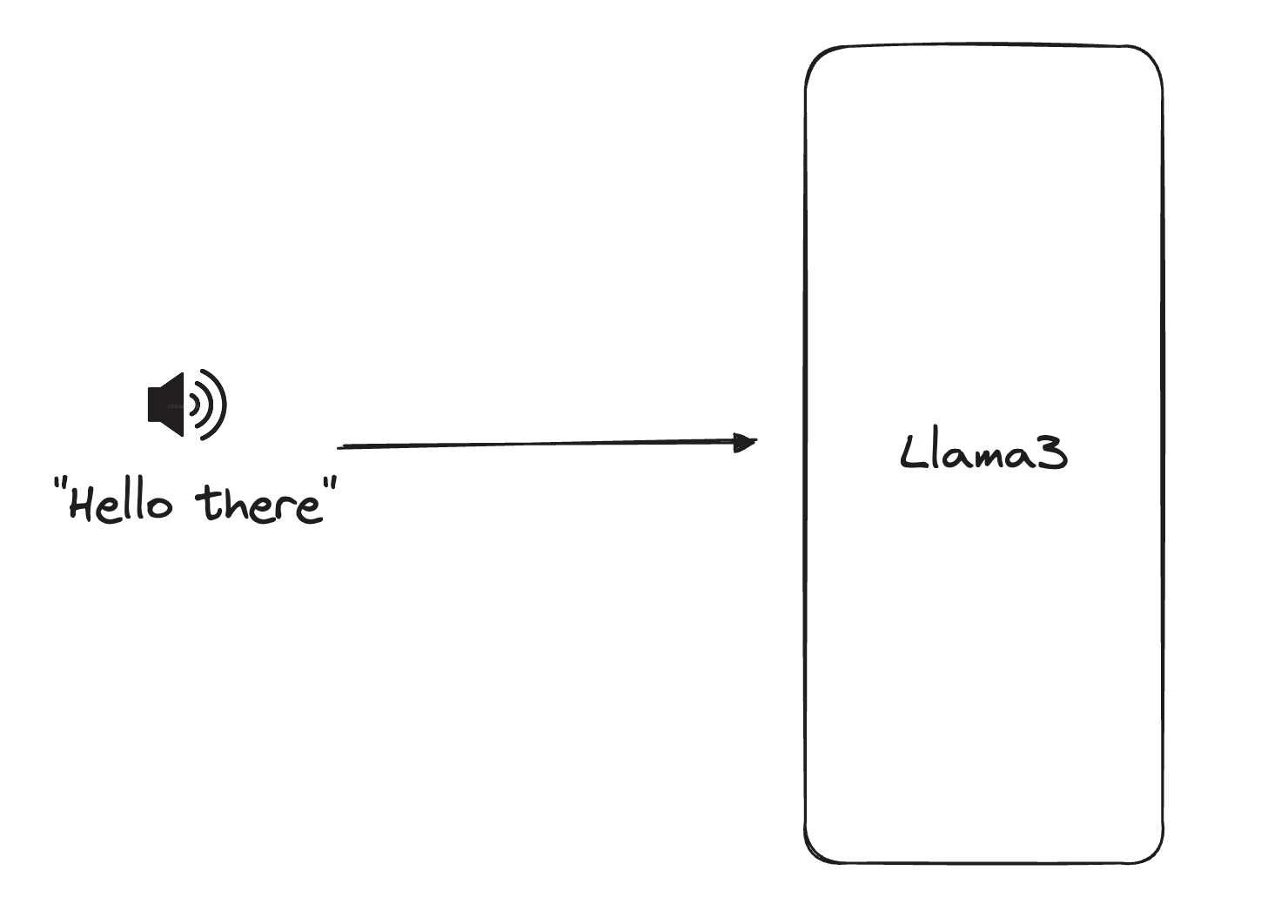 Pictured: Multimodal models natively understand text, audio, image input.
Pictured: Multimodal models natively understand text, audio, image input.
Significant research in this space has been on training multimodal models that natively understand audio tokens and text tokens (see Citations).
Usually, this entails pretraining encoders, adapters on large amounts of ASR, AST, synthetic, and human-generated datasets, making the endeavor quite data expensive and compute intensive.
We wanted to see how far we’d get by just continuously training llama3 on a small set of synthetic, high quality instruct QA pairs. Our initial goal is a small, scaling law experiment, where any initial convergence of audio and text tokens could have interesting implications upon larger and more diverse datasets.
Training: 19th July Checkpoint
This experiment ended up being quite achievable on a smaller budgeted run. Building on existing research, we employed a unique combination of techniques. Hopefully our initial findings below contribute meaningful learnings.
Data: For training data, we collated open datasets, consisting of 6 million (15Bn) Q&A text pairs. This was then reduced to 2Mn instruction pairs (4B tokens) through deduping, and filtering for English (FastText (opens in a new tab)) and token length. We also used additional heuristics-based classifiers to filter out bad samples for additional quality. (See limitations).
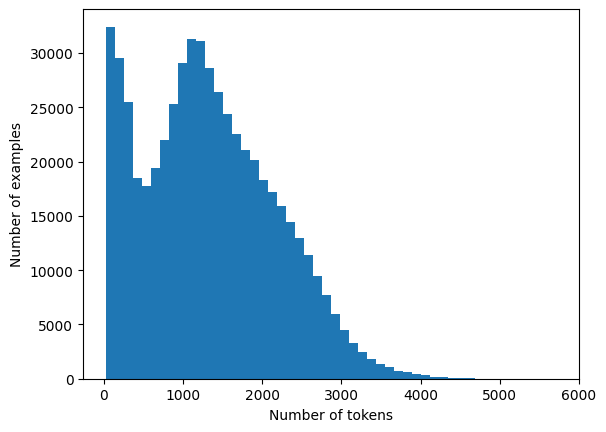
Fig 1. Data tokens length distribution
Audio generation: We then used WhisperSpeech (opens in a new tab) text-to-speech model on the default voice tensor to generate an interleaving dataset of 2bn tokens (1Mn. wav files):
- 80%: audio questions & text answers
- 20%: text questions & text answers (a subset of the 80% audio questions & text answers)
Audio encoding: The Encodec (opens in a new tab) VQ model was used to tokenized the audio files and create sound tokens, compressing each time step into 2D tensors, via 2 channels (24kHz audio file to 1.5 kps) These audio tokens were then added to llama3’s existing token vocabulary. (See limitations).
You can find the datasets here:
| Date | HF Checkpoint | Tokens |
|---|---|---|
| 📅 2024-07-19 | 🔗 https://huggingface.co/homebrewltd (opens in a new tab) | 🔢 1.35B |
| 📅 2024-07-18 | 🔗 https://huggingface.co/datasets/homebrewltd/instruction-speech-v1.55 (opens in a new tab) | 🔢 800M |
| 📅 2024-06-30 | 🔗 https://huggingface.co/datasets/homebrewltd/instruction-speech-v1 (opens in a new tab) | 🔢 450M |
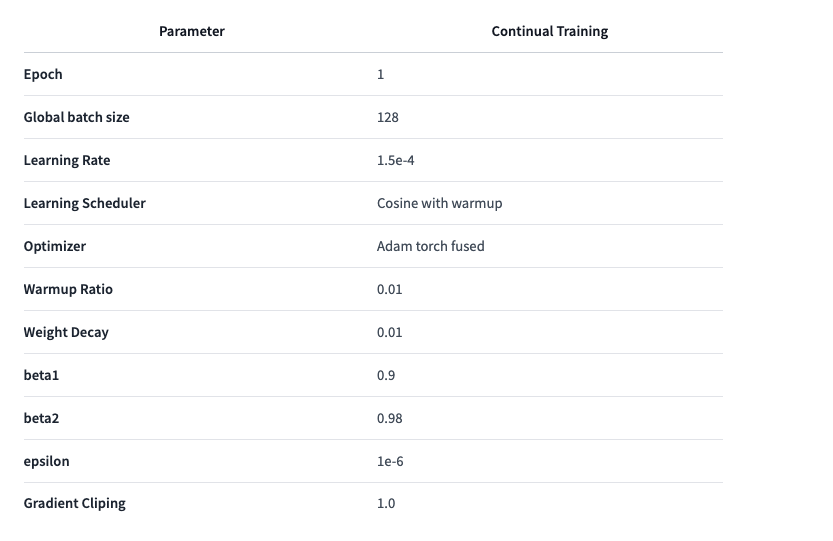
Training: The instruct tuning was done with fsdp2 (Torchtune (opens in a new tab)) mixed-precision, on a llama3 8b (opens in a new tab) base model, with the final weights in bf16. We used the AdamMini (opens in a new tab) optimizer, a global batchsize of 128 (mini-batches of 2-4), a 3e-4 learning rate, and a slightly longer warm up ratio. You can find the full steps to reproduce our training here on Hugging Face (opens in a new tab).
Results: 19 July Run
This checkpoint was evaluated on held-out datasets not overlapping with training data.
Loss Evaluation: After 2 billion tokens, the model stablised at a loss of ~1.0.
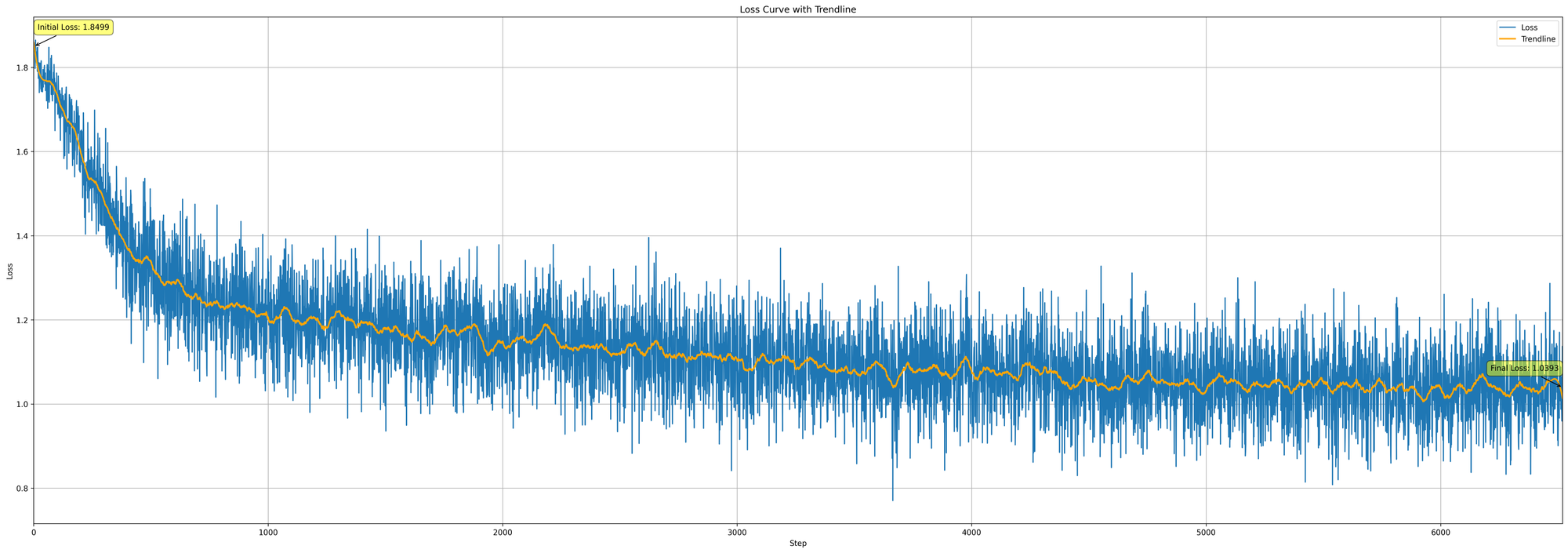 Pictured: checkpoint 7-19 loss curve.
Pictured: checkpoint 7-19 loss curve.
Heuristics Evaluation: We manually evaluated this checkpoint on 100 samples:
A good answer from the checkpoint:
# Question (in audio tokens):
Is the Paris Climate Change agreement going to help slow pollution?
# Expected Output (in text):
Yes, the Paris Climate Agreement is designed to help slow pollution and combat climate change on a global scale. The main goal of the agreement is to limit global warming to well below 2 degrees Celsius, preferably to 1.5 degrees Celsius, compared to pre-industrial levels. To achieve this, countries that have signed the agreement commit to reducing their greenhouse gas emissions...
# Model's Output (in text):
Yes, the Paris Climate Agreement is a global commitment to limit global warming to well below 2 degrees Celsius above pre-industrial levels and pursue efforts to limit it to 1.5 degrees Celsius. The agreement was signed by 195 countries and entered into force on November 4, 2016.
The agreement sets out a framework for countries to reduce greenhouse gas emissions and adapt to the impacts of climate change. It also encourages countries to increase their ambition and to support developing countries in their efforts to reduce emissions.
The Paris Agreement is a significant step towards addressing climate change, but it is not a guarantee of success. The agreement requires countries to submit Nationally Determined Contributions (NDCs) outlining their plans to reduce emissions and adapt to the impacts of climate change. The success of the agreement will depend on the ability of countries to meet their NDCs and to work together to address the global nature of climate change.```Conversely, a bad answer from the checkpoint:
# Question (in audio tokens):
what is the address to configure a mfm harddrive on a pc without a bios
# Expected Output (in text):
Configuring an MFM (Modified Frequency Modulation) hard drive on a PC without a BIOS (Basic Input/Output System) is a complex task that involves hardware jumpers and possibly some low-level software...
# Model's Output (in text):
The average computer memory (RAM) is typically around 4GB, but it can vary depending on the specific model and manufacturer.Many of the bad answers were "sound similar" hallucinations, e.g. the model mishearing Gasoline for Gaslow, which is phonetically similar.
# Question (in audio tokens):
Why is gasoline a liquid.
# Expected Output (in text):
Gasoline is a liquid because it is a mixture of hydrogen and oxygen...
# Model's Output (in text):
Gaslow is a city in Scotland...Degradation Evaluation: We evaluated whether the checkpoint retained original reasoning with 0 shot MMLU.
| Groups | Version | Original | New | Stderr |
|---|---|---|---|---|
| mmlu | 1 | 0.6380 | 0.2478 | 0.0036 |
| - humanities | 1 | 0.5785 | 0.2504 | 0.0063 |
| - other | 1 | 0.7184 | 0.2530 | 0.0078 |
| - social sciences | 1 | 0.7413 | 0.2418 | 0.0077 |
| - stem | 1 | 0.5468 | 0.2448 | 0.0076 |
While this specific checkpoint demonstrated forgetting, it has since been addressed. It was a mistake in our tuning parameters, and a 30 July checkpoint with a similar sized training set yielded 0.6137.
Results:
| Date | Checkpoint | Tokens | Steps | Loss | GPU hours | All in Cost |
|---|---|---|---|---|---|---|
| 📅 2024-07-19 | 🔗 https://huggingface.co/homebrewltd/llama3-s-2024-07-19 (opens in a new tab) | 🔢 1.35B | 🔄 1195k | 📉 1.0 | 112(14x8 H100 SXM) | $530 😂 |
| 📅 2024-07-01 | 🔗 https://huggingface.co/homebrewltd/llama3-s-2024-07-08 (opens in a new tab) | 🔢 700M | 🔄 1431k | 📉 1.7-1.8 | 64(8x8 H100s SXM) | $280 |
| 📅 2024-06-23 | 🔗 https://huggingface.co/homebrewltd/llama3-s-init (opens in a new tab) | 🔢 0M | 🔄 N/A | 📉 N/A | N/A | N/A |
We were pleasantly surprised at the initial results under such compute and data constraints. Though, it is too early to conjecture speech & text convergence.
Minimally, we observed some transitive properties between an LLM’s existing latent text representations and newly learned audio tokens, through just instruct tuning llama3.
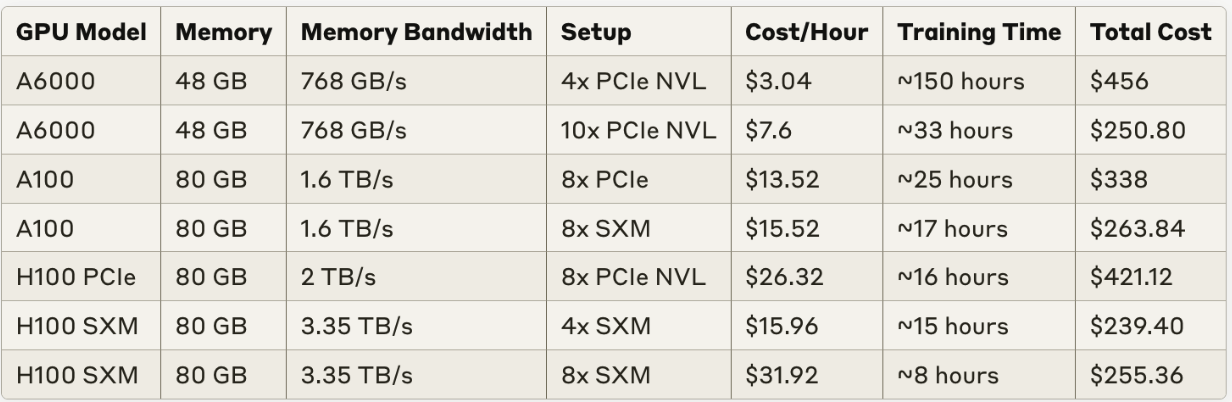
Hardware: for funsies, we ran our training workload cross various nodes, and measured the following.
Current Problems
This 19th July checkpoint had limitations.
- Synthetic audio training data (not to mention our generated from a single voice tensor) have been shown to be less effective than ASR or crowdsourced audio.
- Audio compression encoders like Encodec underperform against semantic encoders, or custom encoders for speech.
- Pre-training and subsequent alignment may be strictly necessary.
- As we scale to bigger datasets or models, scaling laws may imply greater loss or degeneration.
- Possibly suboptimal warming-up ratio, learning rate, minor bugs.
Next Steps
At the moment, we’re working on a new iteration with the following improvements:
- Retraining phase 1 with llama3.1
- A more diverse synthetic speech set and encoder
- Various fixes to hyperparameters, improving degradation
- Training script optimizations and better benchmarking
Have better ideas? Join our training in public (opens in a new tab).
Citations
- The Llama 3 Herd of Models (opens in a new tab)
- Chameleon: https://arxiv.org/abs/2405.09818 (opens in a new tab)
- AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs (opens in a new tab)
- AudioLM: a Language Modeling Approach to Audio Generation (opens in a new tab)
- Speech Recognition with Augmented Synthesized Speech (opens in a new tab)
- DASB: Discrete Audio and Speech Benchmark (opens in a new tab)
- Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models (opens in a new tab)
Open Call
We’re calling on LLM researchers and audio experts to collaborate with us. As a nascent research team, Homebrew is our early days of “throw sh*t at the wall and see what sticks”.
We openly discuss training recipes in Discord, argue it out, and often run the best ideas the next day.
Join the Discord fun:
- #research (opens in a new tab) : general research & paper sharing
- #llama3-s (opens in a new tab): daily
argumentsdiscussions - #research-livestream (opens in a new tab): live training & lo-fi music 😂
We believe that collaborative, open research can accelerate progress in this exciting field. Whether you're an experienced researcher or an enthusiastic newcomer, your contribution could be valuable.
At Homebrew Computer Company (opens in a new tab), we like smaller, “edge friendly” models that are privacy preserving and feasible to train on energy-efficient clusters. Read more about our AI philosophy here (opens in a new tab).


The Soul of a New Machine
To stay updated on all of Homebrew's research, subscribe to The Soul of a New Machine