🍓 Ichigo: Llama Learns to Talk



Homebrew’s early-fusion speech model has evolved. Meet 🍓 Ichigo - the latest llama3-s checkpoint.
Inspired by the Chameleon (opens in a new tab) and Llama Herd (opens in a new tab) papers, llama3-s (Ichigo) is an early-fusion, audio and text, multimodal model. We're conducting this research entirely in the open, with an open-source codebase (opens in a new tab), open data (opens in a new tab) and open weights (opens in a new tab).
 Image generated by ChatGPT
Image generated by ChatGPT
Demo
A real-time demo of 🍓 Ichigo (7th Oct 2024 checkpoint): the MLLM listens to human speech and talks back.
🍓 Ichigo
You can try it for yourself:
- Via our self-hosted demo here (opens in a new tab)*
- Via Hugging Face demo here (opens in a new tab)
- Via Official github repo (opens in a new tab)
- Download Ichigo family (opens in a new tab)
*Inference may slow/queued due to shared compute on a single NVIDIA RTX4090
This post shares methodology and results behind this latest checkpoint. As always, this is just the beginning, and we need your ideas to push this research further.
Changelog
From the llama3-s-v0.2 checkpoint (opens in a new tab), we identified several areas for improvement:
- Pre-training data was English only, limiting multilingual capabilities
- Significant degradation in the base model's (llama3) capabilities, particularly in MMLU (opens in a new tab) performance
- Inability to recognize nonspeech inputs, leading to response hallucinations
- Limited contextual understanding in multi-turn conversations
Ichigo addresses these limitations through a three-phase training approach.
Training
Phase 1: Continual Pre-training on Multilingual Speech
Data: In this phase we shifted from an English-only dataset (opens in a new tab) to 7 languages dataset (opens in a new tab). This helps align the model's distribution more closely with the original multilingual training of the base LLM.
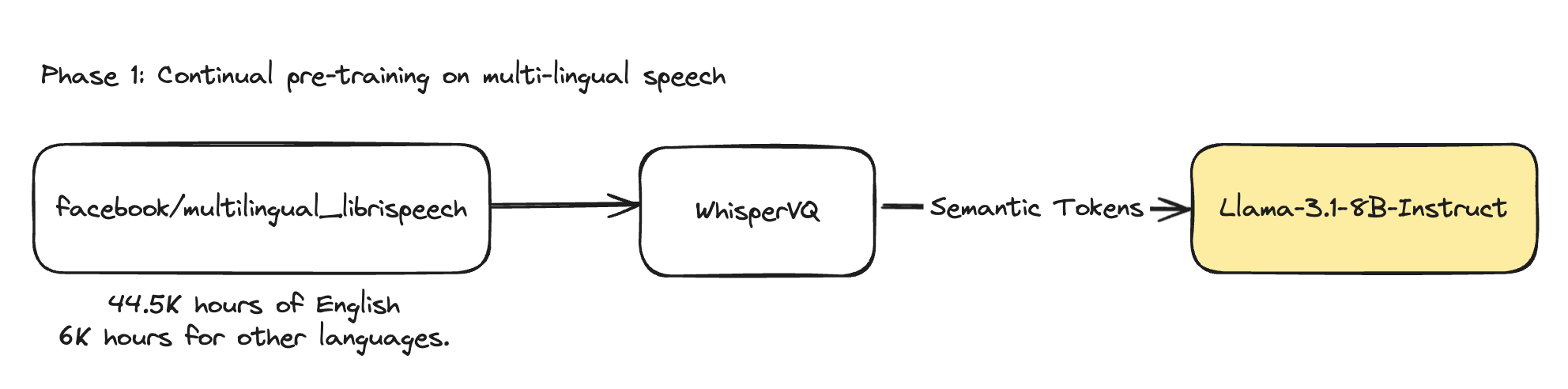 Fig 1. Synthetic data generation pipeline
Fig 1. Synthetic data generation pipeline
Tokenizer: To accommodate our shift towards a multilingual dataset, we made a change in our tokenizer from English-only checkpoint (opens in a new tab) to 7 languages checkpoint (opens in a new tab).
Training: The pre-training totaled 8064 steps and took over 45 hours on 10xA6000s. We used Torchtune’s (opens in a new tab) Fully Sharded Data Parallels 2 (FSDP2), an AdamW Fused optimizer, along with the following parameters:
| Parameter | Continual Training |
|---|---|
| Epoch | 1 |
| Global batch size | 480 |
| Learning Rate | 2e-4 |
| Learning Scheduler | LambdaLR with warmup |
| Optimizer | AdamW Fused (opens in a new tab) |
| Warmup Steps | 50 |
| Weight Decay | 0.005 |
| Max length | 512 |
| Precision | bf16 |
Loss: Training loss converged to just below 2. This loss convergence pattern is similar to what we observed in our previous run (opens in a new tab).
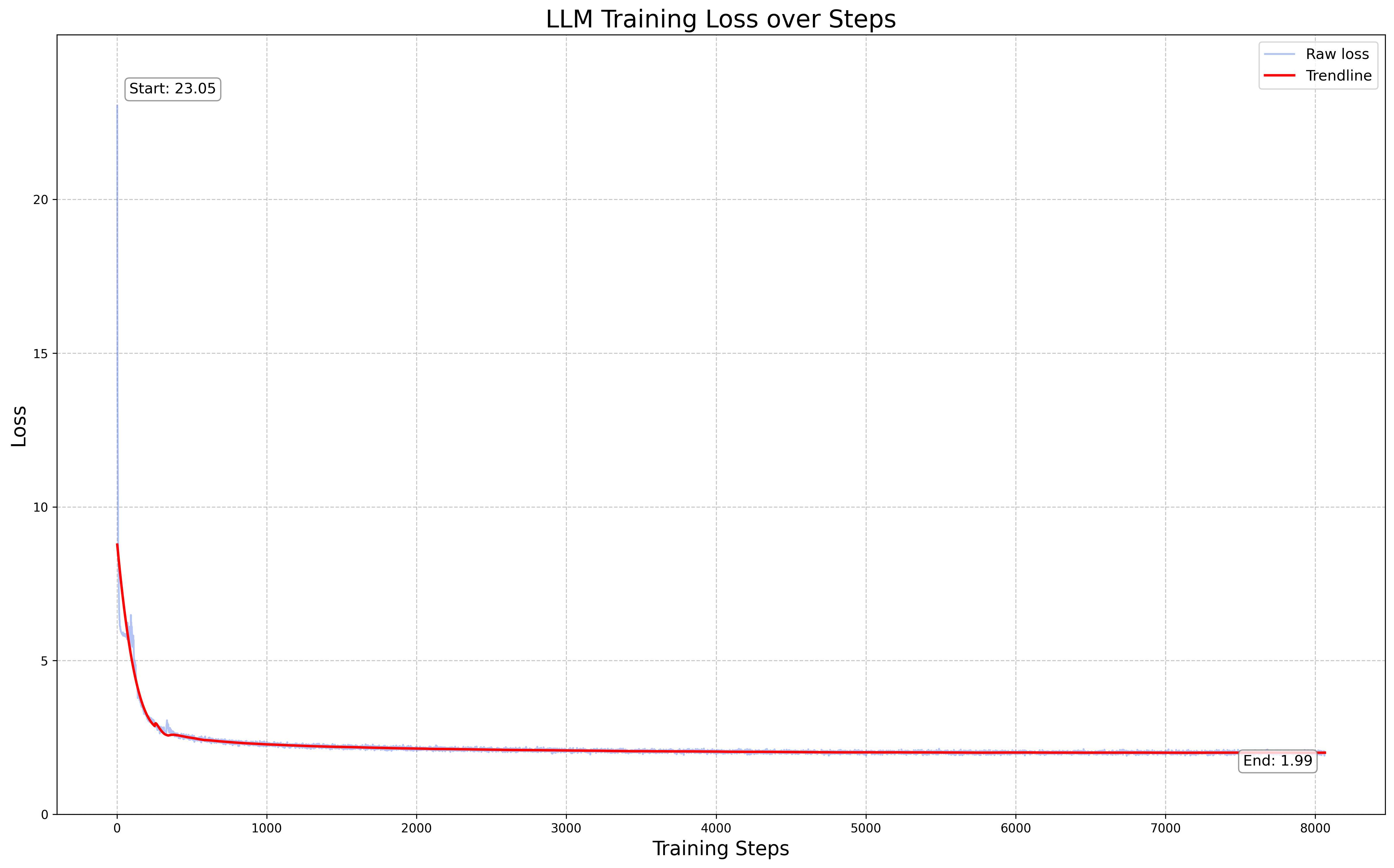
MMLU Eval: We measured MMLU at this stage to get a sense of degradation. 5-shot MMLU dropped from 0.69 (opens in a new tab) → 0.42 This decrease rate is higher than our previous run.
Phase 2: Balancing Original Performance and Speech Modality
This phase focused on recovering the model's general capabilities while enhancing its speech-related skills
Addressing MMLU Performance Drop: The continual pre-training in Phase 1, while necessary for introducing speech capabilities, significantly reduced the model's original performance. This is a common challenge when retraining a pre-trained model on new vocabulary. Our goal was to recover these capabilities without compromising the newly acquired speech understanding.
Spoiler alert: We recovered MMLU performance from 0.42 to 0.63, reducing the degradation rate to approximately 10%.
Optimizing Data and Training Strategies
Data:
- Scale: Increased the data size from 0.92M to 1.89M samples.
- Diversity: Expanded topic range on daily conversation, problem-solving scenarios and math solving.
- Language Focus: It's important to note that despite the scale-up, we maintained an English-only instruction dataset for this phase.
Transcription token: Previously, we used 513 semantic tokens from WhisperVQ's codebook, 2 special tokens for sound input boundaries, and 1 special token for transcription tasks. However, we discovered that the transcription token hindered model recovery.
Our solution:
- Replaced the single transcription token with six diverse prompts
- This approach improved the model's ability to map sound token patterns to corresponding text.
| Test Name | Pretrain Checkpoint | Dataset | SpeechQA data | Instruction-text data | Transcription data | Final MMLU Score |
|---|---|---|---|---|---|---|
| Test 1: Early Pretrain Recovery | 3,000 steps | 500k mixed | ✅ | ✅ | ❌ | 0.55 |
| Test 2: Late Pretrain Recovery | Last | 500k mixed | ✅ | ✅ | ❌ | 0.515 |
| Test 3: Late Pretrain Recovery with Transcription (With transcription token) | Last | 500k mixed | ✅ | ✅ | ✅ | 0.48 |
| Test 4: Extended Late Pretrain Recovery (With transcription prompts) | Last | 1.89M mixed | ✅ | ✅ | ✅ | 0.63 |
Mixed training data between modalities: We determined an optimal interleaving of different data types with 70% speech instruction prompts, 20% speech transcription prompts and 10% text-only prompts.
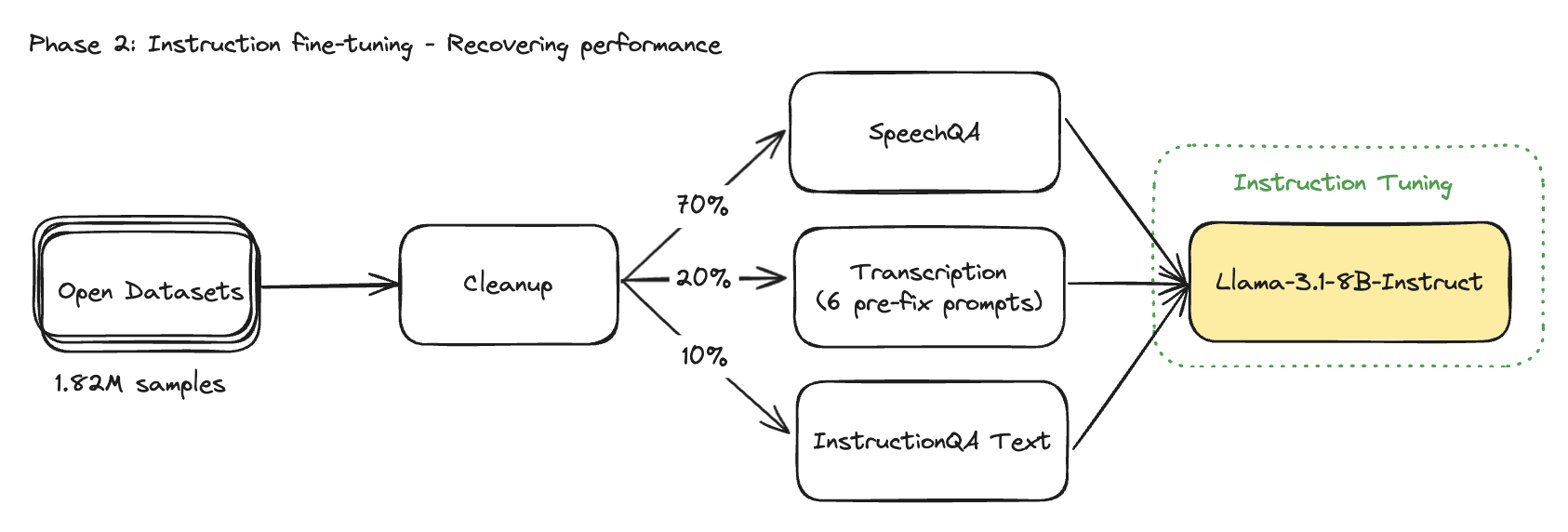
This distribution was not arrived at arbitrarily. We conducted several permutation tests to find the sweet spot that balances speech understanding, transcription abilities, and general language skills.
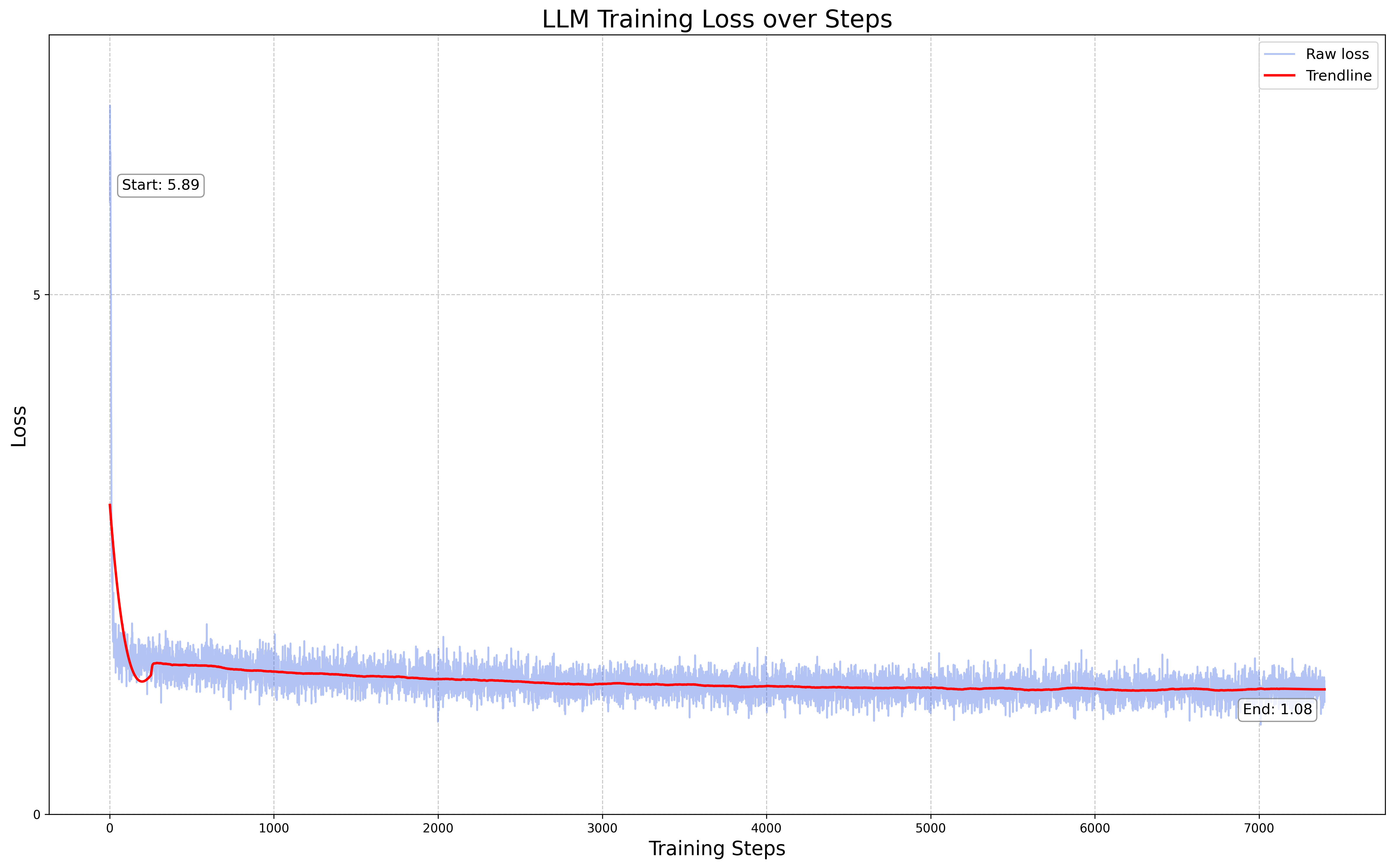
Training: The phase 2 training totaled 7400 steps and took over 10 hours on 8xH100s with the following parameters:
| Parameter | Continual Training |
|---|---|
| Epoch | 1 |
| Global batch size | 256 |
| Learning Rate | 7e-5 |
| Learning Scheduler | LambdaLR with warmup |
| Optimizer | AdamW Fused (opens in a new tab) |
| Warmup Steps | 73 |
| Weight Decay | 0.005 |
| Max length | 4096 |
| Precision | bf16 |
Loss: Training loss converged at 1.08
Phase 3: Teach Ichigo To Say “I cannot hear”
In this final phase, we focused on fine-tuning the model to improve user interaction, particularly in handling inaudible inputs and multi-turn conversations.
Objectives
- Teach the model to recognize and appropriately respond to inaudible inputs
- Improve context retention in multi-turn conversations with speech input
Teach model to say “I cannot hear”
Our initial approach was to create a synthetic dataset of random environmental noises. However, we quickly realized that this method was difficult to scale.
To fix this problem, we hypothesized that meaningful speech typically follows certain patterns. This led us to utilize the 513 sound tokens from the WhisperVQ codebook, and randomize them into similar patterned sequences. This method allowed us to generate a vast amount of "inaudible" input data with a wide distribution. The key insight was that if the model could recognize these chaotic patterns as inaudible input, it would learn to decline responses appropriately.
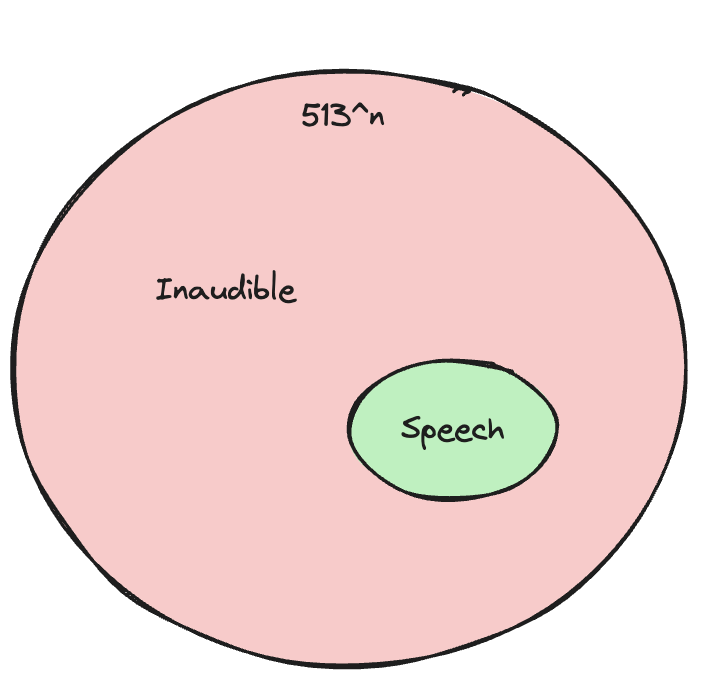 Inaudible space is much larger than Speech space
Inaudible space is much larger than Speech space
To put this in perspective: With an average speech input of about 50 sound tokens, there are 513^50 possible arrangements. However, only a tiny fraction of these arrangements would constitute meaningful speech. By exposing our model to a wide range of these chaotic arrangements, we taught it to distinguish between audible and inaudible inputs effectively.
Data:
Multi-turn Conversation:
To enhance multi-turn capabilities with speech input, we fine-tuned the model using 150K samples. The dataset composition was:
- 90% two-turn conversations
- 10% conversations with four or more turns
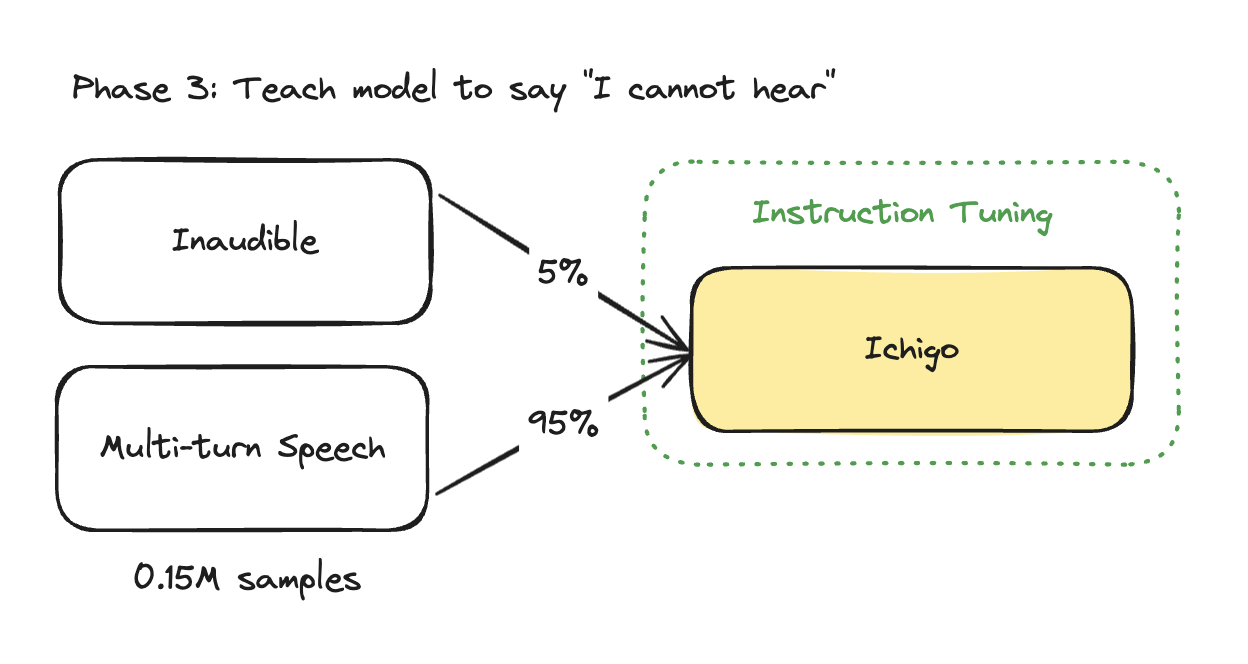
Inaudible Refusal data:
For the inaudible inputs, we employed the Qwen2.5-72B model (opens in a new tab) to generate diverse synthetic answers. This process was facilitated through Distillabel (opens in a new tab), ensuring a wide range of appropriate "decline" responses.
Beyond randomizing sound tokens for inaudible input, we also performed sequence length distribution matching between inaudible and audible data. This ensured a balanced representation of both types of inputs in our training set.
Training: The phase 3 training totaled 644 steps and took over 3 hours on 8xH100s with the following parameters:
| Parameter | Continual Training |
|---|---|
| Epoch | 1 |
| Global batch size | 256 |
| Learning Rate | 1.5e-5 |
| Learning Scheduler | LambdaLR with warmup |
| Optimizer | AdamW Fused (opens in a new tab) |
| Warmup Steps | 8 |
| Weight Decay | 0.005 |
| Max length | 4096 |
| Precision | bf16 |
Loss: Loss converged at 0.98
Results
MMLU: We recovered the MMLU after phase 1 and maintained the instruct following performance after phase 3
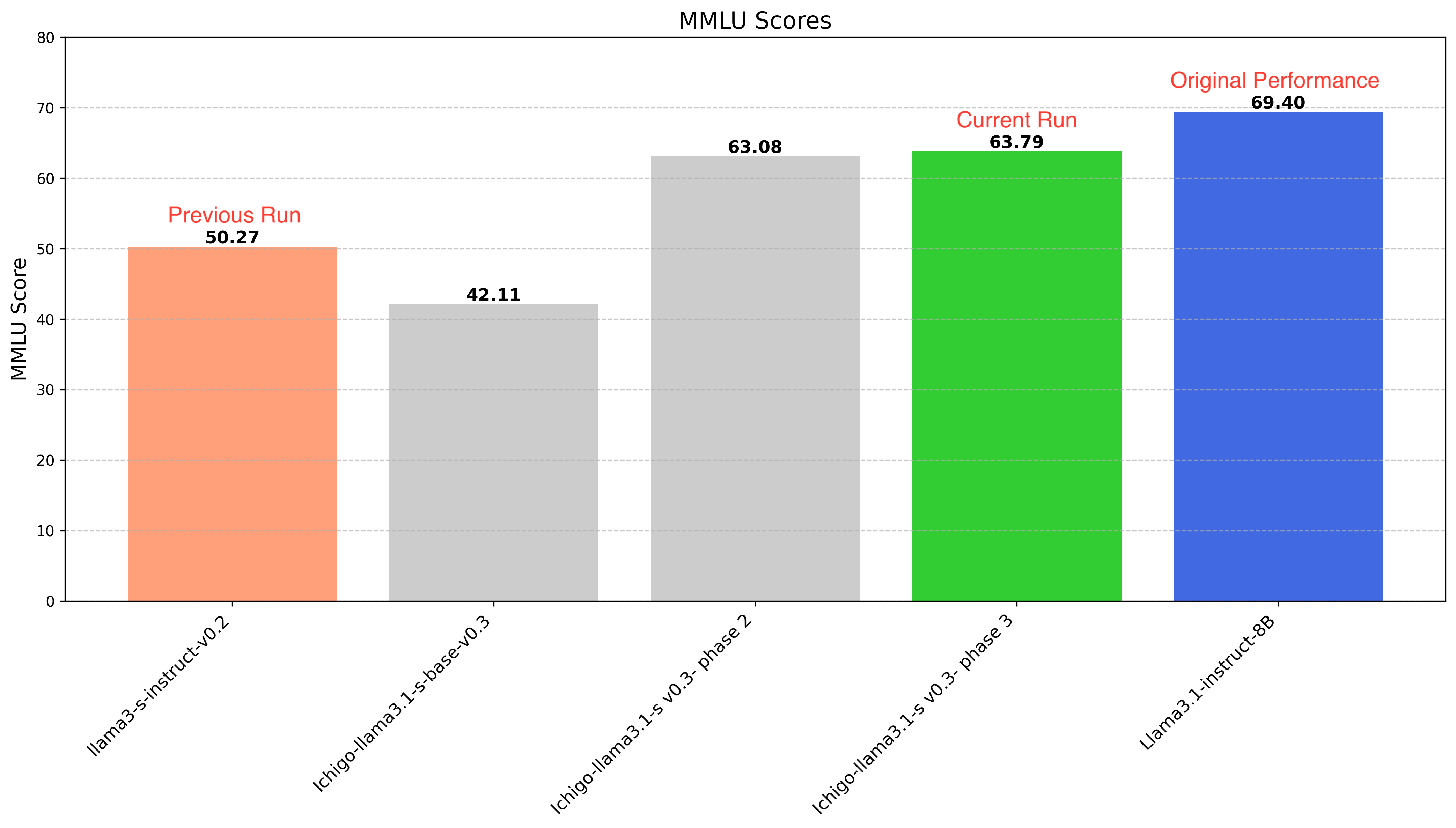
We know that with only MMLU is insufficient to claim recovery. So we will also benchmark on more text-based datasets in our upcoming research paper.
AudioBench Eval: AudioBench (opens in a new tab) is a June 2024 benchmark designed to evaluate audio large language models (AudioLLMs). It measures speech capabilities, in addition to ASR, transcription, etc., through a compilation of many open datasets.
| Model Bench | Open-hermes Instruction Audio (opens in a new tab) (GPT-4-O judge 0:5) | Alpaca Instruction Audio (opens in a new tab) (GPT-4-O judge 0:5) |
|---|---|---|
| Llama3.1-s-v2 (opens in a new tab) | 3.45 | 3.53 |
| Ichigo-llama3.1-s v0.3-phase2 -cp7000 (opens in a new tab) | 3.42 | 3.62 |
| Ichigo-llama3.1-s v0.3-phase2-cplast (opens in a new tab) | 3.31 | 3.6 |
| Ichigo-llama3.1-s v0.3-phase3 (opens in a new tab) | 3.64 | 3.68 |
| Qwen2-audio-7B (opens in a new tab) | 2.63 | 2.24 |
Next steps
🍓 Ichigo is still in early development and has limitations:
- Weak to nonsensical audio in multi-turn conversation
- Multilingual capability hasn’t been fully explored
For now, our next steps are as follows:
- Curate training dataset better, longer prompts, filtering out non-speech-perfect data.
- A more efficient synthetic data pipeline that skips redundant layers
- Establishing cascaded system, baseline, and ASR benchmarks to evaluate computational and improvements across other tasks
Long term, we aim to develop 🍓 Ichigo as a production-level tool that can be integrated in your AI applications.
Appendix
Data distribution:
| Task Type | v0.2 | v0.3 |
|---|---|---|
| Speech Multi-turn | None | 140K samples: 2 turns, 10K samples >= 4 turns |
| Speech QA | 679K samples | 1.33M samples |
| Transcription | 250K samples (Using a special token) | 400K samples (6 different prompts) |
| Noise Audio | None | 8K samples |
| Text-only | None | 100K samples: multi-turn, 50K samples: single turn |
Prompts used for transcription data
Transcribe the following audio clip: <speech>
Convert the spoken words to text: <speech>
What is being said in this audio clip: <speech>
Transcribe the speech in this audio sample: <speech>
Please write down what is being said in the audio clip: <speech>
Generate a transcript from this sound file: <speech>
Recognize the speech in this audio clip: <speech>
Produce a text version of this audio recording: <speech>Acknowledgements
- OpenSLR (opens in a new tab)
- Torchtune (opens in a new tab)
- The Evolution of Multimodal Model Architectures (opens in a new tab)
- Whisper: Robust Speech Recognition via Large-Scale Weak Supervision (opens in a new tab)
- Collabora’s WhisperSpeech (with data from LAION) (opens in a new tab)
- AudioBench: A Universal Benchmark for Audio Large Language Models (opens in a new tab)
- Chameleon: Mixed-Modal Early-Fusion Foundation Models (opens in a new tab)
- Why Warmup the Learning Rate? Underlying Mechanisms and Improvements (opens in a new tab)
- Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model (opens in a new tab)
- The Llama 3 Herd of Models (opens in a new tab)
- Qwen 2.5 (opens in a new tab)
- Distilabel (opens in a new tab)
- MLS: A Large-Scale Multilingual Dataset for Speech Research (opens in a new tab)
- Yip Jia Qi (opens in a new tab): Discrete Audio and Speech Benchmarks (opens in a new tab)
- Discord Contributors (opens in a new tab): @gau.nerst, @hydroxide, @Blanchon.jl
Open Call
We’re calling on LLM researchers and audio experts to experiment with us.
Join the Discord fun:
- #research (opens in a new tab) : general research & paper sharing
- #llama3-s (opens in a new tab): daily
argumentsdiscussions - #research-livestream (opens in a new tab): live training & lo-fi music 😂
We believe that collaborative, open research can accelerate progress in this exciting field. Whether you're an experienced researcher or an enthusiastic newcomer, your contribution could be valuable.
At Homebrew Computer Company (opens in a new tab), we like smaller, “edge friendly” models that are privacy preserving and feasible to train on energy-efficient clusters. Read more about our AI philosophy here (opens in a new tab).


The Soul of a New Machine
To stay updated on all of Homebrew's research, subscribe to The Soul of a New Machine